
TypeScript Declarations aus Spring REST API Metadaten generieren
Was möchten wir erreichen?
Mit Hilfe der Metadaten, die uns Spring Data REST zur Verfügung stellt, können wir für unsere Web Clients automatisch Schema-Definitionen generieren. Somit sparen wir uns unnötige Aufwände durch die sonst notwendige doppelte Definition von Datenmodellen in Java und TypeScript. Dies reduziert weiterhin fehleranfälliges manuelles Aktualisieren dieser Definitionen. Durch ein von mir erstelles NPM Paket kann dieses Verfahren nun in jedes Projekt eingebunden werden.
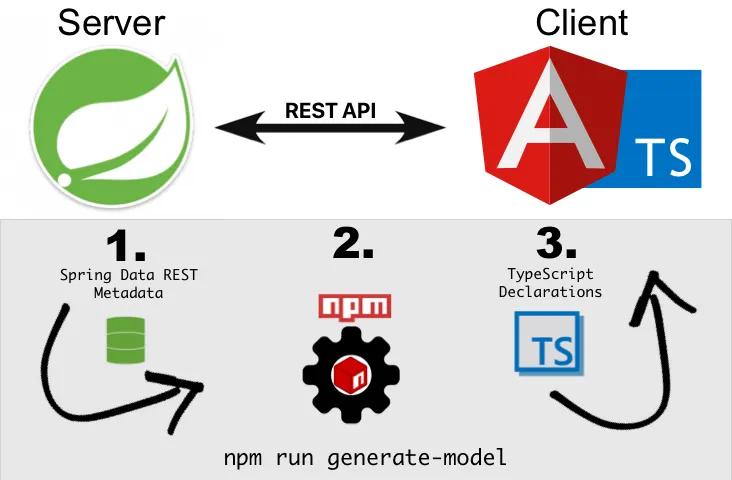
Warum macht dieser Ansatz Sinn?
💡 Keine Lust zu lesen?
Nicht jeder lernt am besten aus Büchern und Artikeln. Lernen darf interaktiv sein und Spaß machen. Wir bieten dir auch Angular Intensiv-Schulungen an, um dich möglichst effektiv in das Thema Angular zu begleiten. Im Kurs kannst du die Fragen stellen, die du nur schlecht googeln kannst, z.B. "Besserer Weg, um meine Applikation zu strukturieren?". Wir können sie dir beantworten.
- ✔ Öffentliche Termine verfügbar
- ✔ Vor Ort, als auch Remote
- ✔ Deutsch/Englisch möglich

Heutzutage ist es üblich, Web Anwendungen in Client und Server Komponenten aufzuteilen: Während der Server (oft auch Back-end genannt) sich um das zugrundeliegende Datenmodell, Datenhaltung und den größten Teil der Business Logik kümmert, wird das User Interface und Verhalten, das den Nutzer betrifft, im Allgemeinen mit JavaScript, HTML und CSS auf dem Client (oft auch als Front-end bezeichnet) realisiert, d.h. im Browser des Nutzers.
Häufig kommen dabei Frameworks wie Angular zum Einsatz, um die Entwicklung zu beschleunigen und Code besser lesbar und generell zugänglicher zu machen, z.B. indem eine standardisierte Struktur für Projekte vorgegeben und bestimmte Code Artefakte an bestimmte Stellen platziert werden, so dass Entwickler, die sich in einem Projekt noch nicht auskennen, sich dennoch schnell zurecht finden.
Die zwei Seiten einer solchen Web Anwendung kommunizieren typischerweise mittels HTTP-basierter RESTful APIs, die vom Server bereit gestellt werden. Diese klare Trennung zwischen Client und Server hat zahlreiche Vorteile, z.B.:
- Flexibilität: Die Implementierung der Business Logik ist nicht an eine spezielle Technologie gebunden.
- dynamischeres Verhalten der Anwendung beim Nutzer statt statisch generierter Seiten
- Skalierbarkeit: Server und Client können unabhängig voneinander deployed werden. Außerdem läuft der Client auf dem Rechner des Nutzers und hat daher nicht notwendigerweise direkte Auswirkungen auf die Nutzung von Server Ressourcen.
- Offline Fähigkeit: Selbst wenn der Server nicht erreichbar ist, kann die Anwendung weiterlaufen (siehe Progressive Web Apps (PWAs)) und sich wieder synchronisieren, sobald der Server wieder verfügbar ist.
Dennoch, wie bei fast jedem design pattern, bringt dies auch Nachteile mit sich. Einer davon ist, dass das clientseitige Datenmodell mit seinem serverseiigen Gegenstück synchron gehalten werden muss. Wenn man nicht dauerhaft darauf achtet, werden das Server und das Client Model mit der Zeit unvermeidlich divergieren, was die Software wiederum deutlich schwerer wartbar macht.
Wie funktioniert das Paket?
Es gibt nun einige Ansätze, dieses Problem zu lösen, ohne dass man diese Arbeit manuell machen muss. Einer dieser Ansätze ist die Nutzung von Swagger und / oder OpenAPI. Mit diesen Werkzeugen lassen sich APIs definieren und anschließend clientseitige SDKs mittels Swagger Codegen generieren, um auf APIs zuzugreifen, so dass man diese nicht selber programmieren muss.
Momentan bin ich in der Erstellung eines Workflow Tool involviert, das Spring Data REST für die Bereitstellung von REST-Ressourcen und Spring REST Docs zur Dokumentierung dieser API nutzt (eine Aufgabe, die sonst oft ebenfalls an Swagger delegiert wird. Denn obwohl Swagger ein umfassendes Werkzeug zum Arbeiten mit APIs ist, ist dessen offensichtlichster und direktester Nutzen die Bereitstellung einer automatisch generierten, für Menschen lesbaren API Dokumentation). Was die Entwicklung des Clients angeht, werden für dieses Workflow Tool Angular und TypeScript verwendet.
Hier wäre also eine API Definition, aus der man einen TypeScript Client generieren könnte, sehr sinnvoll.
Daher dachte ich mir: “Spring REST Docs stellt ebenfalls eine maschinenlesbare API Definition zur Verfügung, weil es nicht allein zum Dokumentieren von APIs genutzt werden.” Tatsächlich ist dies lediglich ein Nebenprodukt seines Hauptzwecks: Zugängliche Acceptance Tests für APIs zu schreiben, die gleicherma0en als API Definition und Dokumentation dienen.
Also recherchierte ich ein wenig und fragte ein wenig herum, konnte aber nicht wirklich etwas geeignetes finden. Etwas verwirrt, weil ich mir nicht vorstellen konnte, wirklich der einzige mit diesem Problem zu sein, fiel mir plötzlich auf, dass ich viel zu kompliziert gedacht hatte: Spring Data REST stellte bereits selbst Metadaten über APIs zur Verfügung, insbesondere über die verwendeten Datentypen!
Normalerweise geschieht diese in einem Format namens Application-Level Profile Semantics (ALPS). Obwohl dieses Format sicherlich sinnvoll ist, eignet es sich nicht besonders, um in JavaScript (oder TypeScript wie im Falle von Angular) Applikationen verarbeitet zu werden.
Allerdings besteht alternativ die Möglichkeit, application/schema+json als Accept Header an Spring Data REST Endpoints zu senden, woraufhin diese mit Metadaten in einem JSON Schema Format antworten.
JSON Schema wiederum lässt sich sehr gut zusammen mit Angular and TypeScript verwenden. Zum Beispiel gibt es Libraries, die dynamisch Formulare aus mit JSON Schema definierten Datentypen generieren.
Darüber hinaus gibt es json-schema-to-typescript von Boris Cherny, das beinahe das ist, wonach ich suchte. Diese Library nimmt JSON Schema Dateien entgegen und erstellt daraus TypeScript Deklarationen.
Was allerdings noch fehlte, war eine Möglichkeit, nicht nur einfach eine einzelne JSON Datei - oder mehrere davon - einzulesen, sondern über alle REST API Endpoints zu iterieren, die vom Server per HTTP bereit gestellt werden und deren Metadaten dann jeweils zu verarbeiten.
Daher habe ich ein npm Package mit dem Namen spring-data-rest-json-schema-to-typescript-definitions erstellt, das dieses Problem in einer wiederverwendbaren Weise löst.
Benutzung des Paketes
Paket via NPM installieren
npm install spring-data-rest-json-schema-to-typescript-definitions --save-dev
package.json erweitern
In eurer package.json könnt ihr das script nach der Installation wie folgt einbinden.
In diesem Beispiel habe ich es unter dem Namen generate-model angelegt.
{
...
"scripts": {
...
"generate-model": "node node_modules/spring-data-rest-json-schema-to-typescript-definitions/dist/index.js http://localhost:8080 ./src/app/generated-model"
...
},
...
}
Die index.js nimmt hierbei zwei Argumente entgegen:
-
Die URL eures API Endpoints der genutzt werden soll, um die Metadaten abzufragen. Hierbei hängt das Script
/profilean die URL und ruft die Spring Data Metadaten ab. -
Der Ordner in den die TypeScript Decleations geschrieben werden sollen.
Ausführen
Habt ihr das nach eur spezifischen Projektkonfiguration angepasst, könnt ihr mit folgendem Befehl die Declarations erstellen und aktuallisieren.
npm run generate-model
💡 Hat dir das Tutorial geholfen?
Wir bieten auch Angular-Intensiv-Schulungen an, um dich möglichst effektiv in das Thema Angular zu begleiten. Im Kurs kannst du die Fragen stellen, die du nur schlecht googeln kannst, z.B. "Besserer Weg, um meine Applikation zu strukturieren?". Wir können sie dir beantworten.
- ✔ Öffentliche Termine verfügbar
- ✔ Vor Ort, als auch Remote
- ✔ Deutsch/Englisch möglich
Fazit
Dies wird hoffentlich anderen - mein zukünftiges Ich inklusive - ermöglichen, darauf in ihren Angular (bzw. generell TypeScript-basierten) Applikationen darauf aufzubauen. TypeScript Declarations auf diese Weise zu generieren, sollte dabei helfen, Datenmodelle zwischen Client und Server synchron zu halten und damit die Software Qualität insgesamt zu verbessern.
Weitere Informationen finden sich im spring-data-rest-json-schema-to-typescript-definitions GitHub Repository, sowie der Projekt Dokumentation.

Björn Wilmsmann
Freiberuflicher Softwareentwickler, Berater und Trainer
Björn Wilmsmann ist selbständiger IT Berater. Er realisiert Softwarelösungen und Anwendungen im Geschäftsumfeld. Er unterstützt Unternehmen in Sachen Software Qualität und gibt Schulungen bei der Einführung neuer Technologien und Prozesse
Werde Teil unserer Community
Seit 2013 bieten wir Tutorials, Artikel und Schulungen rund um Angular. Mit 18 Meetups und über 10.000 Entwickler:innen sind wir die größte Angular-Community in Europa.
Jetzt beitretenWeitere Artikel

Abschätzung der Komplexität einer Angular Anwendung
Häufig machen Angular-Anwendungen einen wesentlichen Teil der Komplexität einer Anwendung aus. Ein kleines Ruby-Script hilft bei der Bewertung.

Mit Angular und Electron zur Desktop-Anwendung
Anwendungen wie Spotify machen es vor: Desktop-Anwendungen werden immer öfter mit Webtechnologien erstellt. Wir helfen dir und erklären die Grundlagen.

Tests in Angular - 9 Beispiele zeigen dir, wie es geht
Wie teste ich meine Angular Anwendung? Wir zeigen dir in 9 leicht zu befolgenden Beispielen wie ihr Services, Komponenten und alle weiteren Konzepte testet.
